- Parasitic Extraction 및 Metal Layer Stack Rc Extrac
- Vlsi Cad Rents Rule이란
- 싱가포르 여행기 뉴턴 맥스웰 호커 푸드 센터
- 내가 보려고 만든 반도체 자료 모음집 반도체 검색 꿀팁
- 2025 신년사 반도체로 빛나는 대한민국의 새 아침
- 과학기술정책 Bio Tech 곧 Gdp 대비 의료비 20 비율의 시대가 옵니다
- 과학기술조직론 과학기술 스타트업 창업 후 운영 방안
- 제 2차 세계대전과 미국의 과학기술 발전 Mit Rad Lab 오펜하이머 Los Alamo
- 과학기술조직론 Team Building
- 부자와 Stem 엘리트들 한국 탈출 이유
중국의 AI/LLM시장: Baidu Ernie bot, Alibaba Tongyi Qianwen, Tencent Hunyuan
최근 인공지능(AI)의 발전은 빠르게 가속화되었고, 그 중심에는 대형 언어 모델(LLM, Large Language Model)이 자리하고 있습니다. 전 세계적으로 OpenAI의 ChatGPT, Anthropic의 Claude, Google의 Gemini가 잘 알려져 있지만, 중국은 위 LLM을 자국 내에서 모두 금지하고, 독자적인 LLM 개발에 집중하며 글로벌 AI 경쟁에서 강력한 입지를 다져가고 있습니다.
그리고, 중국은 정말 많은 대학생, 석박사들이 졸업하고, 중국이 발표하는 AI 연구 양은 세계1위입니다.
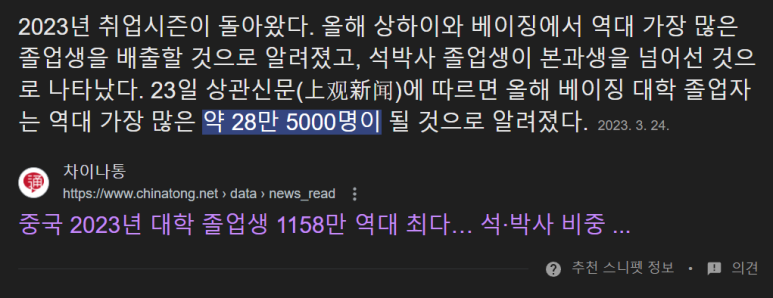
흔한_중국의_1년_대학_졸업자수.jpg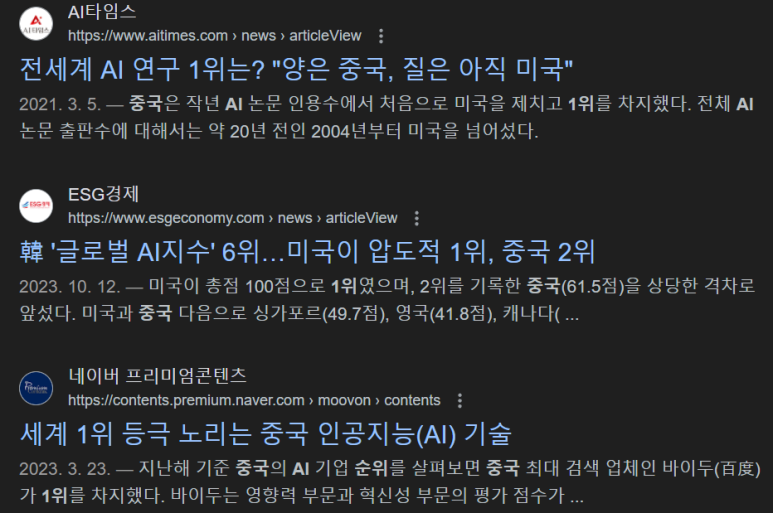
중국의 기술 대기업인 바이두(Baidu), 텐센트(Tencent), 알리바바(Alibaba)가 이끌고 있는 중국 LLM들은 특히 중국어 처리 능력에서 뛰어난 성과를 보이고 있습니다. 이 글에서는 반도체 전공자들이 이해하기 쉽게 중국의 대표적인 LLM을 분석하고, 이들이 글로벌 모델과 어떻게 비교되는지 살펴보겠습니다.
Baidu의 文心一言(Ernie Bot)
바이두의 文心一言, Wenxin Yiyan(ERNIE Bot)은 2023년 3월에 출시되어 현재 4.0 버전까지 진화한 중국의 대표적인 LLM입니다. 이 모델은 중국어 텍스트 처리에서 강력한 성능을 발휘합니다.
이는 바이두가 중국의 검색 엔진 시장을 지배하고 있기 때문에, 검색 관련 작업에서 뛰어난 결과를 보여준다고 생각이 됩니다. 최근 비교 자료는 없지만, 2023년 10월에 비교한 자료 기준으로는 Chat GPT3.5와 비슷한 수준이라고 하는데, 현재는 어떤지 모르겠습니다.
어쨌든 이또한 Python 코드 같은 것들은 잘 짜주는 편이라 CSDN에서 중국 개발자들 평이 좋네요.

본 제품은 Baidu가 인공지능 분야에서 10년 이상 집중적인 연구 끝에 개발한 AI 챗봇으로, 산업 수준의 지식 강화 문학 모델 등 다양한 AI모델를 보유하고 있으며, 중국내 제일 많은 사용자를 보유하고 있습니다.
NVIDIA 칩 구매 제한이 있는 중국이 하드웨어쪽에 병목이 있었고,
얼마전까지 삼성파운드리와 함께 자체칩 설계 “Kunlun project”를 하다가 요즘 소식이 없습니다.

대신, Linjiu microelectronics사의 GP201을 사용하고 있는듯.
사양이 AMD 2014년 수준 그래픽 성능 이상 나오고 있다고 합니다.

그리고 좀 기대되는 반도체가 Biren Technology사의 BR100.
tsmc의 cowos 패키징과 함께 hbm2e, 7nm 공정으로 나왔음. CUDA 대용으로 “SUPA”라는 것을 만들었다는데, CUDA랑 거의 똑같다고 합니다.

https://hc34.hotchips.org/assets/program/conference/day1/GPU%20HPC/HC2022.BirenTech.MikeHong.LingjieXu.v01.pdf제공된 Benchmark를 보면 Throughput도 A100을 넘어섬.
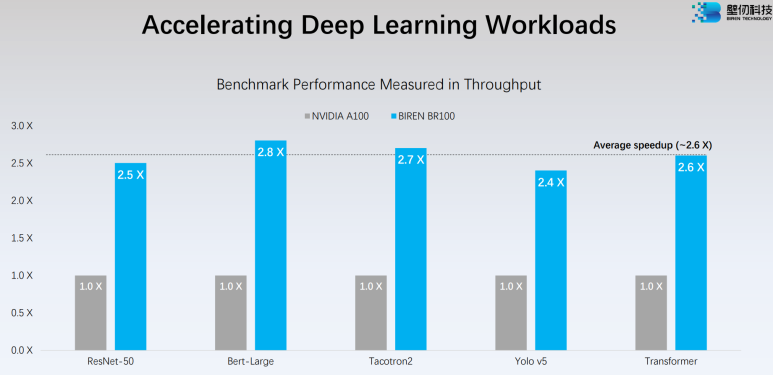
아무튼 이런 칩들이 NVIDIA 칩과함께 Ernie Bot에 사용된다고 합니다.
Ernie Bot이 중국 개발자들을 통해 여기저기 쓰이고 있는데, 그 중 재밌는 것 중 하나가
UBTECH에서 만드는 로봇.


Alibaba Cloud의 Tongyi Qianwen
Alibaba Cloud는 오픈 소스 커뮤니티에 Tongyi Qianwen(Qwen) 모델 시리즈를 제공합니다.
대규모 언어 모델(LLM)인 Qwen, 대규모 언어 비전 모델인 Qwen-VL,
대규모 언어 오디오 모델인 Qwen-Audio, 코딩 모델인 Qwen-Coder
수학적 모델인 Qwen-Math가 포함됩니다.
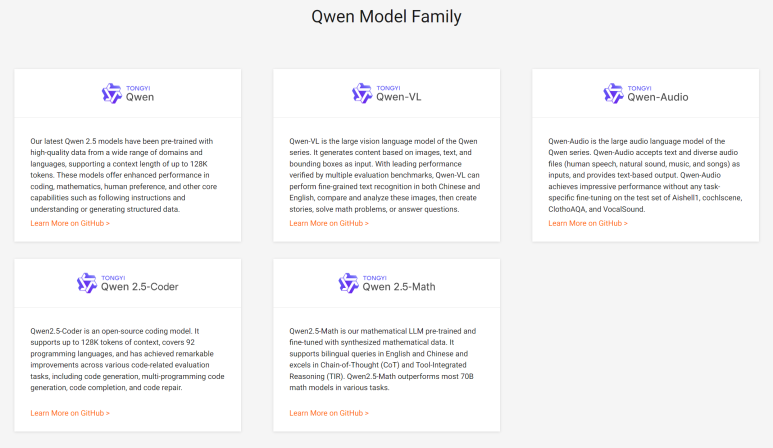
Qwen 2.5 모델은 최대 18조 개의 토큰을 포함하는 최신 대규모 데이터 세트에서 사전 학습되었습니다. Qwen2.5-Coder는 5.5조 개의 코드 관련 데이터 토큰에서 학습되어 코딩 평가 벤치마크에서 Chat GPT등과 비교해도 비슷하게 웃도는 성능이라고 Alibaba는 주장합니다.
Qwen2.5-Math는 중국어와 영어를 모두 지원하며 Chain-of-Thought(CoT), Program-of-Thought(PoT), Tool-Integrated Reasoning(TIR)을 포함한 다양한 추론 방법을 통합한다고 하네요.
Chat GPT가 아직 넘사벽인 것 같기는 한데, Alibaba가 클라우드 사업도 크게 하고 있고,(GPU만 10만개가 넘음.)
해당 모델이 오픈소스라는 점을 생각하면, 앞으로 성장속도가 기대됩니다.
그리고, 2024년 5월 기준으로 중국 전역의 90,000개 이상의 기업 고객이 사용하고 있다고 보고했습니다.

알리바바는 반도체 사업부를 갖고 있습니다.
T-HEAD라는 회사.
Tencent의 Hunyuan
중국에서 결제와 메신저를 쥐고 있는 Tencent는 Hunyuan 모델을 갖고 있습니다.
Hunyuan 모델은 Tencent가 독자적으로 개발한 대형 모델로, 성능이 뛰어나고 에너지 소비가 낮다는 특징이 있다고하는데,,,
비축된 반도체가 엄청 많고, 가격이 싸고 에너지소비가 낮다는데, 이외 다른 소개는 모르겠습니다.
그런데 중국사람들은 결제, 채팅, SNS, 회의 등등 텐센트에 기대되는 기능은 많습니다.

https://hunyuan.tencent.com/
腾讯混元 : 腾讯研发的大语言模型
ByteDance의 Doubao
얘네는 더 싸다고 합니다. 근데 파라미터 개수는 공개되지 않았습니다.
1위안(0.14USD)당 200만개의 토큰을 처리 할 수 있다고 합니다.
OpenAI에서 가벼운 모델인 GPT-4o model의 경우, 5달러로 100만 토큰을 처리 할 수 있습니다.
아래 Doubao모델 링크를 걸어두었으니 한번 사용해보세요. 중국어만 가능합니다. (그래서 요즘 중국어 공부하고 있음.)

https://www.doubao.com/chat/
결론
중국의 LLM 개발은 빠르게 진행되고 있으며, 앞으로의 발전 가능성도 큽니다. 중국 정부의 AI 규제와 보호주의 정책은 중국내 AI 기업들이 기술을 더욱 발전시킬 수 있는 환경을 제공하고 있다고 생각이 듭니다.
앞으로 중국의 LLM이 글로벌 시장에서 경쟁력을 높이기 위해서는 다국어 지원, 실생활 적용 능력의 개선이 필요하고, 하드웨어에서 발생하는 병목 현상을 중국이 어떻게 해결해나갈지 궁금하네요.
계속 업데이트 하겠습니다.
.
해시태그 :