- Parasitic Extraction 및 Metal Layer Stack Rc Extrac
- Vlsi Cad Rents Rule이란
- 싱가포르 여행기 뉴턴 맥스웰 호커 푸드 센터
- 내가 보려고 만든 반도체 자료 모음집 반도체 검색 꿀팁
- 2025 신년사 반도체로 빛나는 대한민국의 새 아침
- 과학기술정책 Bio Tech 곧 Gdp 대비 의료비 20 비율의 시대가 옵니다
- 과학기술조직론 과학기술 스타트업 창업 후 운영 방안
- 제 2차 세계대전과 미국의 과학기술 발전 Mit Rad Lab 오펜하이머 Los Alamo
- 과학기술조직론 Team Building
- 부자와 Stem 엘리트들 한국 탈출 이유
반도체 미세화 한계, 극복 방안: Forksheet, CFET, High-NA EUV
자율주행, VR/AR, 인공지능…
엄청나게 큰 데이터를 빠르게 처리해야합니다. 그러면서도 제한된 자원으로 사용 가능해야합니다.
이러한 급속한 수요 증가로 인해 컴퓨팅 파워에 대한 수요가 폭발적으로 증가하고 있습니다.
이것을 기능적으로 구현하는 것은 Software이지만, 실제로 구동되는 곳은 반도체입니다.
그리고 성능과 전력에 대한 최적화는 대부분의 혁신은 반도체 회로 설계, 반도체 공정 설계, 반도체 재료 수준에서 결정됩니다.
앞으로 컴퓨팅 수요가 계속 늘아날 것은 당연해보입니다. 이러한 기하급수적으로 증가하는 데이터를 지속 가능한 방식으로 처리하려면 고성능 반도체 기술의 개선이 필요합니다.
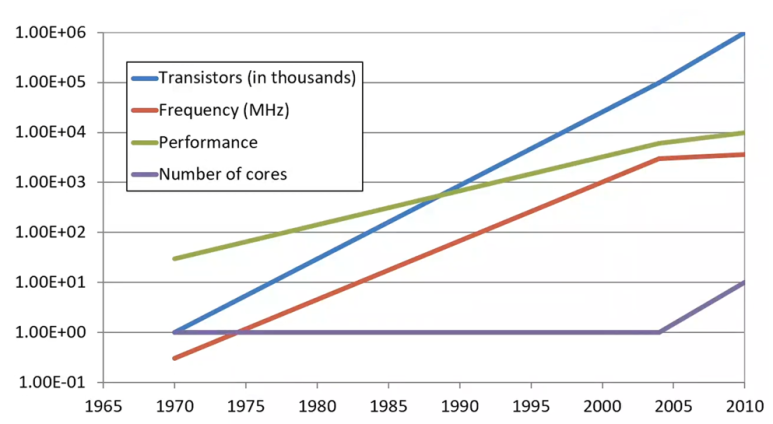
반도체 성능 및 전력의 최적화는 대부분 “무어의 법칙과 데나드 스케일링”을 따라 진화했습니다.
3줄로 요약하면,
(1) 무어의 법칙: 반도체 산업은 2년마다 집적도가 2배씩 높아짐
(2) 데나드 스케일링: 집적도가 높아질 수록 성능과 전력 효율이 좋아짐
(3) 그런데 미세공정의 수율이 너무 낮아서 양산 경제성이 없고, 너무 미세해지니 데나드 스케일링도 안 먹힘.
IMEC에서는 “더 작고, 더 빠르고, 더 나은 반도체” 양산에 성공하기 위해서 다섯 가지 도전 과제를 동시에 해결해야한다고 주장합니다.
전세계의 어떤 기업도 처음부터 끝까지 다 할 수 없습니다. 반도체 생태계 전반의 공동 혁신과 협력을 통해 무어의 법칙을 지속할 수 있습니다.
이것이 imec의 향후 15년에서 20년 동안의 야심찬 로드맵에서 제시된 핵심 메시지입니다.
Five walls at a time
- The scaling wall: 순수 lithography 기반의 scaling 속도가 점점 느려지고 있습니다. Microchip과 transistor의 개별 구조가 원자 크기에 가까워짐에 따라 quantum 효과가 microchip의 작동에 간섭하기 시작하면서 scaling이 점점 더 어려워지고 있습니다.
https://en.wikipedia.org/wiki/Multiple_patterning
Multiple patterning - Wikipedia : This article may be too technical for most readers to understand . Please help improve it to make it understandable to non-experts , without removing the technical details. ( December 2022 ) ( Learn how and when to remove this message ) Multiple patterning (or multi-patterning ) is a class of techno…
- The memory wall: 시스템 성능은 core와 memory 사이의 data 경로 제한에 직면해 있습니다. 사실 memory bandwidth는 processor 성능을 따라가지 못하고 있습니다. 초당 연산 수(flops)는 늘어나고 있지만, memory bandwidth는 초당 gigabyte로 여전히 제한됩니다.
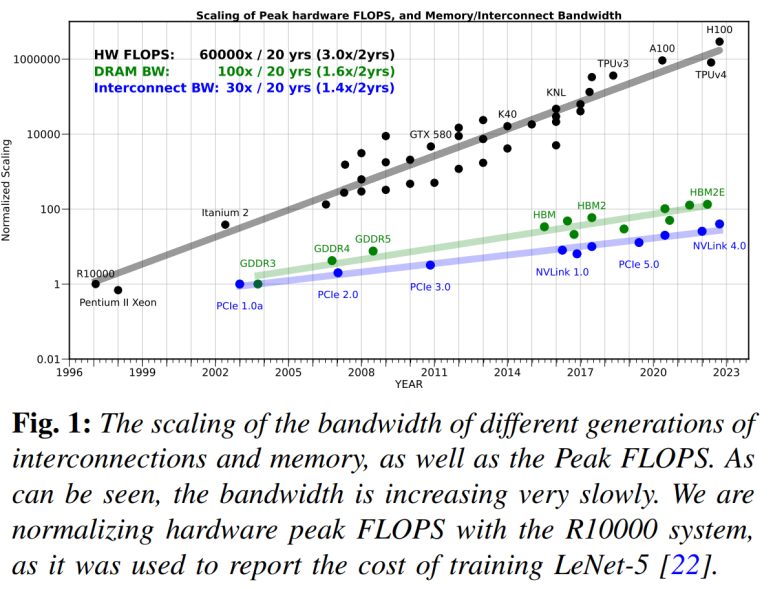
Reference: AI and Memory Wall Amir Gholami1,2 Zhewei Yao1 Sehoon Kim1 Coleman Hooper1 Michael W. Mahoney1,2,3 Kurt Keutzer1 1University of California, Berkeley 2 ICSI 3LBNL https://arxiv.org/pdf/2403.14123
- The power wall: chip에 전력을 공급하고 chip package에서 열을 제거하는 것이 점점 더 어려워지고 있어, 전력 공급과 냉각 개념의 개선이 필요합니다.
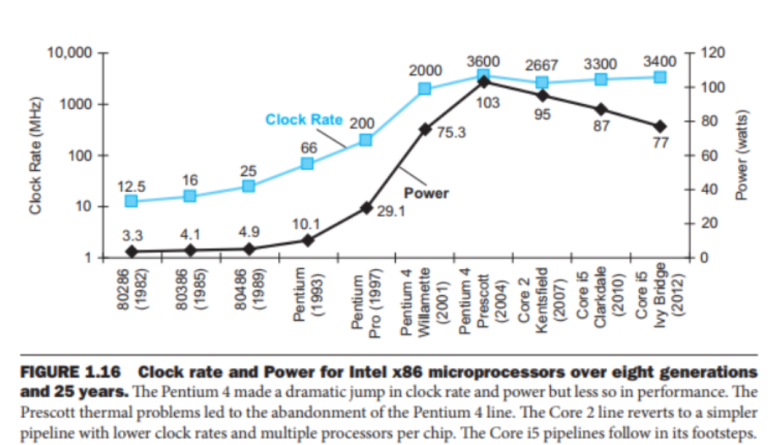

Reference: http://www.edwardbosworth.com/My5155_Slides/Chapter01/ThePowerWall.htm4. The sustainability wall: semiconductor 장치 제조는 greenhouse gas 배출, 물, 천연자원 및 전기 소비 등 환경에 미치는 영향을 증가시키고 있습니다.
반도체 제조에는 비용이 따릅니다. 반도체 제조는 대량의 에너지와 물을 필요로 하며, 유해 폐기물을 생성합니다. 그러나 이 문제를 해결하기 위해서는 공급망 전체가 협력해야 하며, 생태계 접근 방식이 필수적입니다.
목표는 반도체 산업 전체의 탄소 발자국을 줄이는 것입니다.
반도체 제조부터 데이터센터까지.
https://www.youtube.com/watch?v=8qM_nbF5N1M&t=3s
| [](https://www.youtube.com/watch?v=8qM_nbF5N1M&t=3s) |
설명 : Samsung Semiconductor makes environmental sustainability a priority in every facet of our business. We strive to build a sustainable future by developing tec…
- The cost wall: 당연히 chip 제조 비용은 복잡성이 증가함에 따라 폭발적으로 증가할 수 있으며, 이는 design과 process 개발 비용에도 영향을 미칩니다.
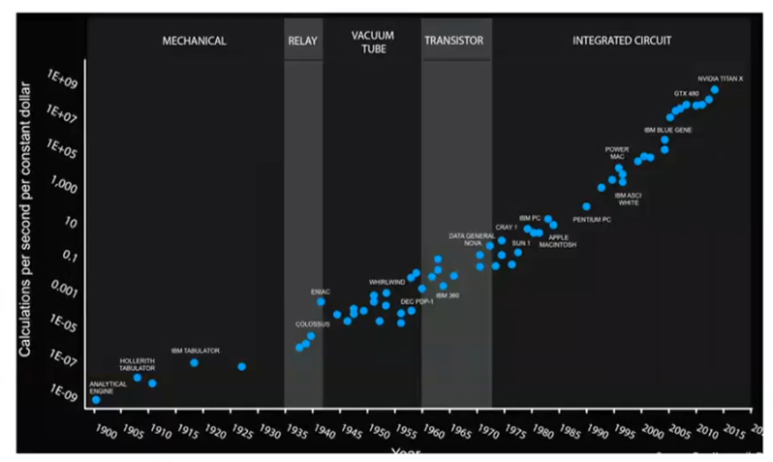
아래 자료는 USD Dollar당 Transistor의 가격입니다.
과거 공정에서는 공정이 작아질 수록 제조 단가도 싸졌는데, 지금은 공정이 너무 미세해지다보니, 수율도 나빠지고 제조 난이도도 높아져서 가격이 높아지고 있습니다.
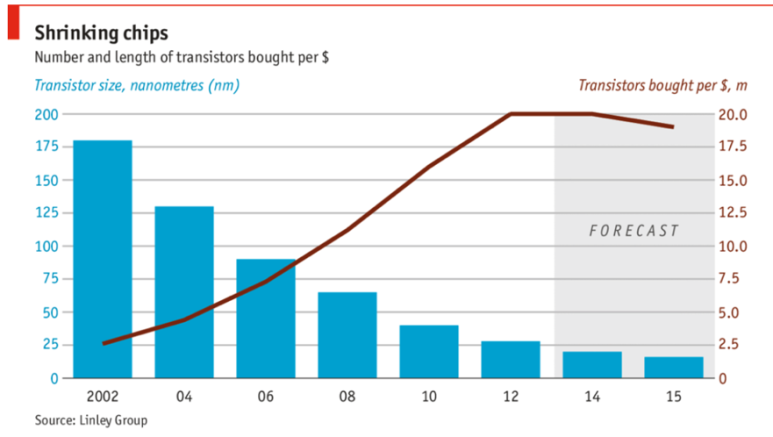
반도체의 가격 의미에서 무어의 법칙이 종말했다고 볼 수 있습니다.
아래 자료는 반도체 설계를위한 비용 Portion 자료입니다.
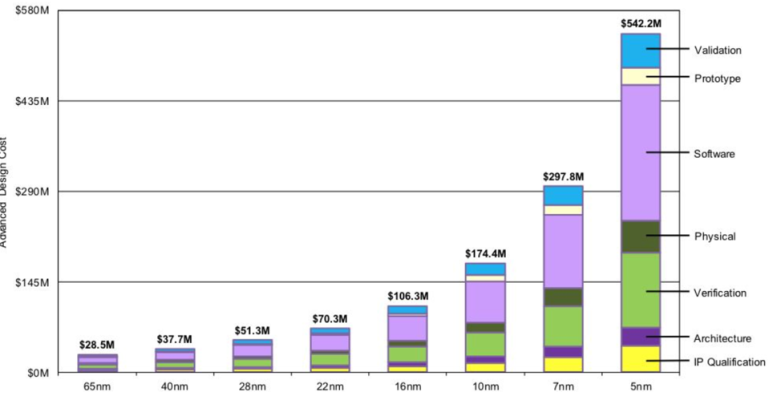
Tearing down the walls
언론해서는 집적 회로(이하 Intergrated Circuit)의 Transistor 수가 약 2년마다 두 배가 된다고 처음 주장한 Gordon Moore의 예언은 종말했다고 합니다.
사실 공정 미세화는 계속 진행이 되고 있습니다. 1nm보다 작은 트랜지스터들도 발표가 되고 있구요.
문제는 양산이 어렵다는 것입니다. 불량률이 99.*% 이런 수준으로 발생하면 당연히 쉽지 않겠죠.
특히 Dennard scaling과 전통적인 Von Neumann computing architecture를 고수할 경우 더욱 그렇습니다.
imec의 scaling 로드맵은 회로 설계의 architecture부터 트랜지스터의 기본구조, materials의 근본적인 변화를 시사합니다.이 로드맵은 2036년까지 0.2nm, 즉 2 ångström까지 도달할 예정이며, 2년에서 2년 반의 주기로 발전을 이어나갈 것으로 예상하고 있습니다.
다가오는 2025년의 Transistor 공정은 GAA라고 불리는 Gate All Around transistor입니다.
SAMSUNG은 3nm 공정에서 GAA를 최초로 도입하고, tsmc는 3nm공정까지는 FinFET 공정을 사용했습니다.
그 결과 삼성은 3nm에서 고전을 겪었고, tsmc는 순방했는데 아직 GAA 양산 경험은 없는거죠.
그래서 2nm공정의 Market share는 어떨지 궁금하네요.
Lithography의 지속적인 발전이 차원 스케일링에 핵심이 될 것입니다. 전통적인 lithography는 빛을 사용하며, 현재 빛의 파장은 필요한 패턴 정확도보다 큽니다. 그래서 Extreme UV(EUV) lithography가 도입되었습니다.
13.5nm 정도의 빛의 파장을 갖는데, 이걸 여러번 그려서 2nm 같은 로직 반도체를 설계 할 수 있죠.

중국 같은 경우에는 EUV 장비를 미국에서 허가를 안 해주기 때문에, 좀 더 멀티패터닝 기술과 노광장비 활용에 대한 기술들을 많이 쓰고있습니다. 그리고 5nm 정도 수준 양산 아직 못 하고 있구요.
High-NA EUV
일단 2nm까지는 EUV가 계속 쓰일 것입니다. 더 작은 크기를 위해서는 고정밀 렌즈를 사용하는 업그레이드된 EUV 버전, 즉 high-NA EUV가 필요합니다.
이 렌즈는 직경이 1meter에 달하며 20pico meter의 정확도를 가질 것입니다. ASML이 개발 중인 high-NA EUV의 첫 번째 프로토타입은 2023년에 나올 예정이며, 대량 제조에의 도입은 2025년 또는 2026년경으로 예상됩니다. 제조 도입에서의 리스크를 줄이기 위해 imec은 ASML과 협력하여 마스크 기술, 습식 또는 건식 UV resist 사용 재료, metrology 및 optics 특성화와 같은 핵심 요소들을 개발하는 매우 집중적인 프로그램을 운영하고 있습니다.
한양대학교 안진호 교수님이 High NA 기술을 한국어로 자세히 풀어서 설명해주셨습니다.
https://www.youtube.com/watch?v=YKnWaXc_sHI&t=1s

설명 : 반도체 EUV ‘High NA’ 기술 원리를 알아봅시다 ①#EUV #HighNA #ASML[반도체 EUV ‘High NA’ 기술 원리를 알아봅시다 ②] 영상 링크https://youtu.be/ZBC7bkc3WyQ00:35 EUV-IUCC 한양대학교 EUV 산업협력센터 소개02:36…
https://www.youtube.com/watch?v=ZBC7bkc3WyQ

설명 : 반도체 EUV ‘High NA’ 기술 원리를 알아봅시다 ②#EUV #ASML #펠리클00:05 ASML과 TSMC가 펠리클을 만들 수 있는 이유01:21 펠리클의 개발 현황06:59 펠리클 소재와 그래핀09:05 멀티패터닝11:03 인텔의 High-NA 도입과 13:28 ASML에…
Gate All Around 혹은 Nanosheet Transistor
동시에 트랜지스터 architecture에서의 혁신도 필요합니다. 현재 tsmc는 FinFET, 삼성은 4nm까지 FinFET을 사용해 microchip을 제작하고 있습니다. 그러나 3nm 세대에 진입하면 FinFET은 quantum 간섭으로 인해 microchip 작동에 방해가 발생합니다.
그래서 3nm에서 tsmc는 개선된 FinFET인 FinFlex를 사용하고, SAMSUNG은 GAA를 도입하였습니다.
tsmc는 2nm부터 GAA를 도입 할 것으로 보입니다.
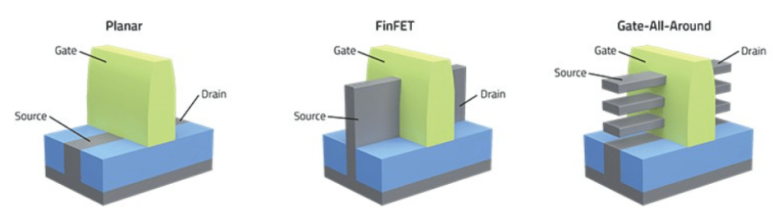
Source: Lam Researchnanosheet 스택으로 구성되어 성능과 short channel 효과를 개선합니다. 이 architecture는 2nm 이후부터 필수적입니다. 삼성, 인텔, TSMC와 같은 주요 칩 제조업체들은 이미 3nm 및/또는 2nm 노드에 GAA 트랜지스터를 도입할 것이라고 발표했습니다.
GAA의 다음 Transistor: Forksheet FET
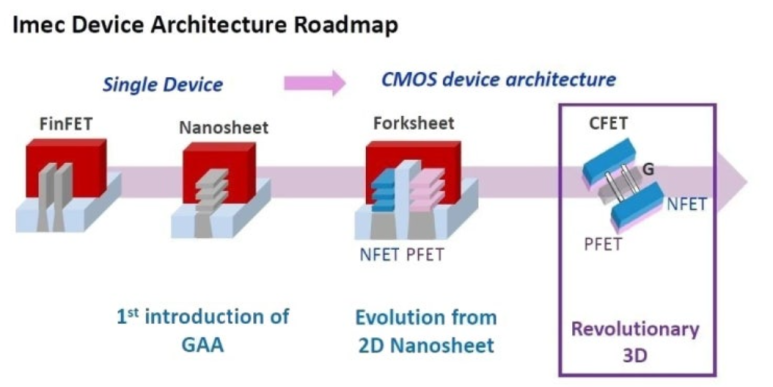
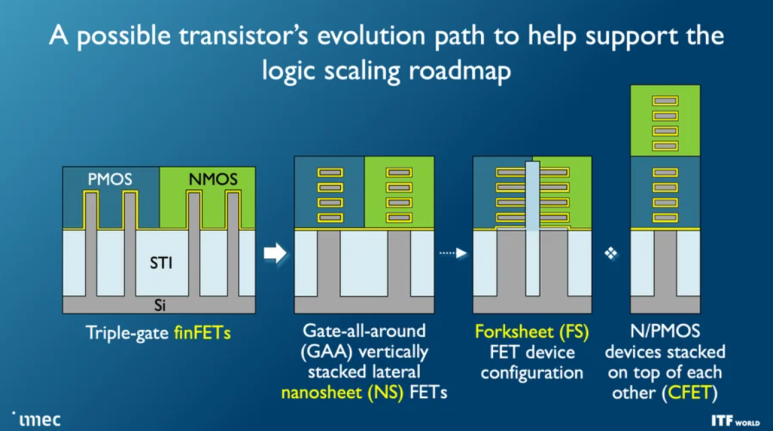
forksheet 트랜지스터는 imec이 발명한 것으로, nanosheet 트랜지스터보다 밀도가 높아 GAA 개념을 1nm 세대까지 확장할 수 있습니다. 이 architecture는 음극과 양극 채널 사이에 장벽을 도입하여 채널 간 거리를 더 가깝게 만들며, 이를 통해 셀 크기를 20% 줄일 수 있습니다.
https://www.youtube.com/watch?v=GO6IF_ymUL8

설명 : Nanosheets, or more generally, gate-all-around FETs, mark the next big shift in transistor structures at the most advanced nodes. David Fried, vice president…
Forksheet의 다음 Transistor: Complementary FET
추가적인 scaling은 음극과 양극 채널을 서로 위에 쌓아 올리는 방식, 즉 Complementary FET(CFET) 트
랜지스터로 실현될 수 있습니다. 이는 GAA의 복잡한 수직 후속작으로, 밀도를 크게 향상시키지만 Transistor Source 와 Drain에 접촉하는 공정 복잡성이 증가하는 대가를 치르게 됩니다.
시간이 지나면서 CFET 트랜지스터는 원자 두께의 초박형 2D 단층 materials인 Tungsten disulfide(WS2)나 molybdenum과 같은 새로운 materials를 포함하게 될 것입니다. 이 device 로드맵과 lithography 로드맵을 결합하면 우리는 ångström 시대에 도달할 수 있습니다.
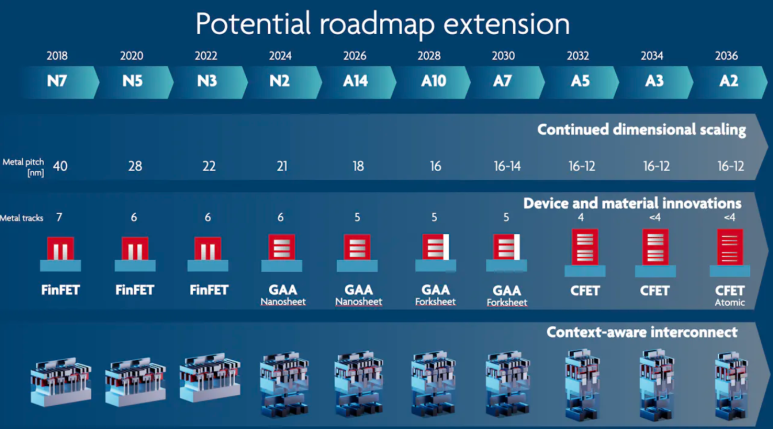
Reference: IMEC, Smaller, better, faster: imec presents chip scaling roadmap2nm에 존재하는 2가지 도전과제
- Memory Wall:
Memory 반도체는 Logic 반도체의 성능을 따라가지 못하고 있습니다.
그러니까 Logic 반도체가 아무리 빨라도, 외부 메모리들이 느려서 데이터 병목현상이 발생합니다.
이런 문제 때문에,
메모리<->로직반도체 버스 구조인, 폰-노이만의 구조를 탈피하여 뉴로모픽 구조로 가고….
메모리를 쌓고…
공정을 미세하게 만들고….
메모리에서 어느정도 로직 처리를 할 수 있게 만들고…
아니면 애초에 로직반도체에 메모리를 넣어버리고….
IO 속도를 높이기 위해 SI/PI 노이즈 저감 기술을 사용하고…
PIM, HBM, CXL, 인터포저, 3D IC 이런 기술들이 정말 매일 나오고 있습니다.
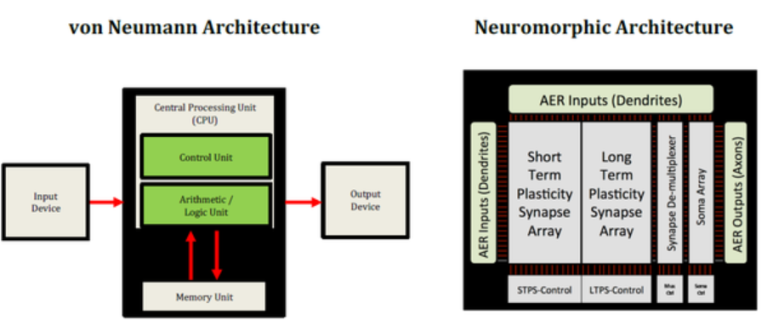
Processor는 memory에서 data와 instructions가 제공되는 속도보다 빠르게 실행될 수 없습니다. 이 ‘memory wall’을 허물기 위해서는 memory가 chip에 더 가까워져야 합니다. Memory wall을 허무는 흥미로운 접근 방식 중 하나는 현재 인기 있는 chiplet 접근 방식을 넘어서는 3D system-on-chip(3D SOC) 통합입니다. 이 이질적인 통합 접근 방식에서는 시스템을 개별 칩으로 분할하고, 세 번째 차원에서 동시에 설계 및 상호 연결합니다.
예를 들어, level-1-cache를 위한 SRAM memory 레이어를 core logic device 바로 위에 쌓음으로써, 빠른 memory와 logic 간 상호작용을 가능하게 할 수 있습니다. 모듈 외부에서의 극도로 높은 대역폭 연결을 달성하기 위해 광학 인터커넥트를 photonics interposer에 통합하는 기술이 개발되고 있습니다.
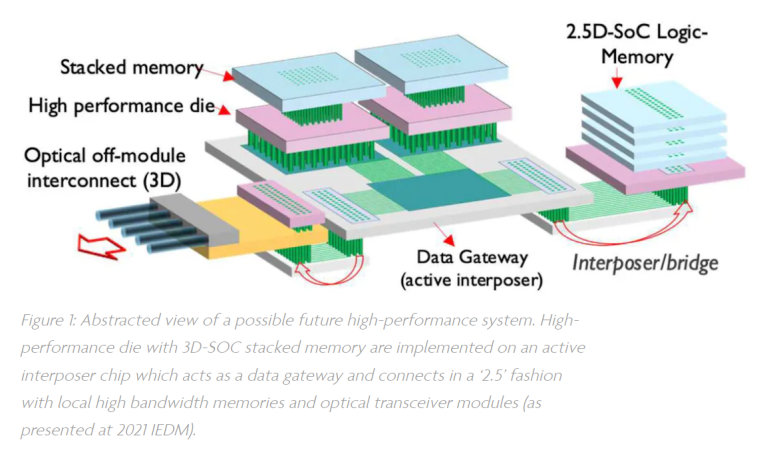
Source: IMEC, Imec highlights benefits of 3D-SOC design and backside interconnects for future high-performance systems
- System-related challenges:
chip이 2.5D, 3D로 진화하면서 열을 빼내는 것이 점점 더 어려워지고 있습니다.
현재 전력 분배는 wafer의 상단에서 시작해 8~20개의 metal layer를 거쳐 트랜지스터에 이릅니다. 그리고 EDA Tool들도 이것에 대한 개발이 막 시작된 수준이구요.
공정에서는 Back side PDN, Nano through silicon vias, 낮은 저항의 재료들이 연구되고 있습니다.
해시태그 :