Process In Memory(PIM)는 기존의 컴퓨팅 구조와는 다른 새로운 접근 방식을 제공합니다.
기존의 컴퓨팅 모델은 데이터를 주 메모리에서 가져와서 중앙 처리 장치(CPU)에서 처리하는 방식을 취하는데, 이로 인해 데이터 이동과 데이터처리를 하며 병목 현상이 발생하여 성능을 제한하는 요인이 됩니다. 하지만 PIM은 이러한 문제를 극복하기 위해 프로세서와 메모리와 결합하여 데이터 처리를 동시에 처리하는 기술을 말합니다.
어떻게 더 빠른 Chip을 만들 것이냐.. 어떻게 대역폭을 늘릴 것이냐 고민을 하다 나온게 PIM이라는 것이죠.
기존 방식 :
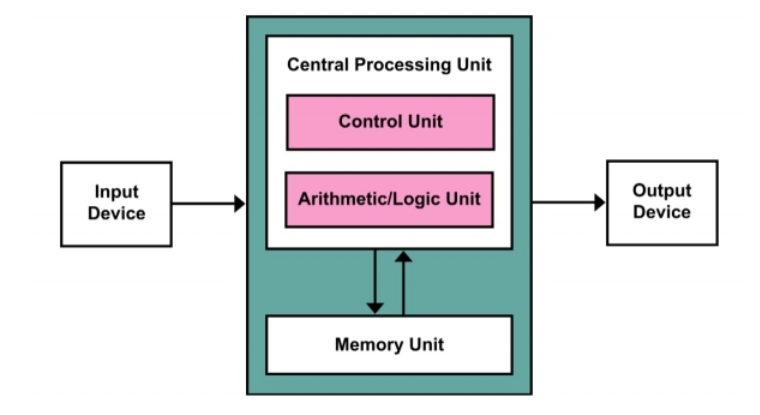
컴퓨터와 사용자는 I/O로 인터페이스하고,
컴퓨터 내에 CPU가 memory와 인터페이스 했는데,
Memory <-> Processor 간 왔다갔다 하는 시간이 굉장히 오래걸리고… 대부분 AI들이 이쪽에서 병목현상이 생긴다는 것을 발견함.
엄청나게 많은 데이터를 CPU까지 옮기는 것에 많은 clock이 쓰이고, 이것을 CPU 하나로 다 처리하는 것도 엄청나게 오래걸리고, 이걸 다시 메모리에 실어야하니… 이게 굉장히 비효율적이라는 생각이 들게됨.
심지어 작은 연산이더라도 processor까지 왔다갔다 하려면 엄청나게 많은 clock이 소요.
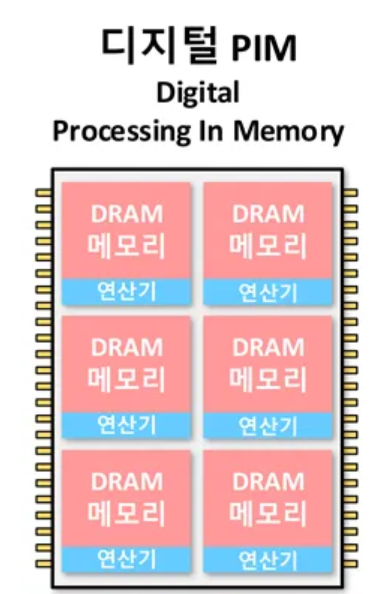
메모리에다가 small processor를 추가해서, 작은 연산들은 Memory 자체에서 처리하고,
큰 연산은 Memory에서 많은 small processor로 1차적인 data 처리를 한 후에 Main Processor에 보내면 더 빠르겠다~ 라는 컨셉이 PIM의 기본이라고 보면 된다.
메모리와 small processor간에 거리가 가까워지기 때문에 높은 frequency로 만들고.. 몇 active clock edge 만에 메모리 <-> Small processor간 연산이 끝나게 된다.
그리고 small processor에서 병렬적으로 1차적인 연산을 한 후에, Main Processor에서 큰 연산을 처리한다.

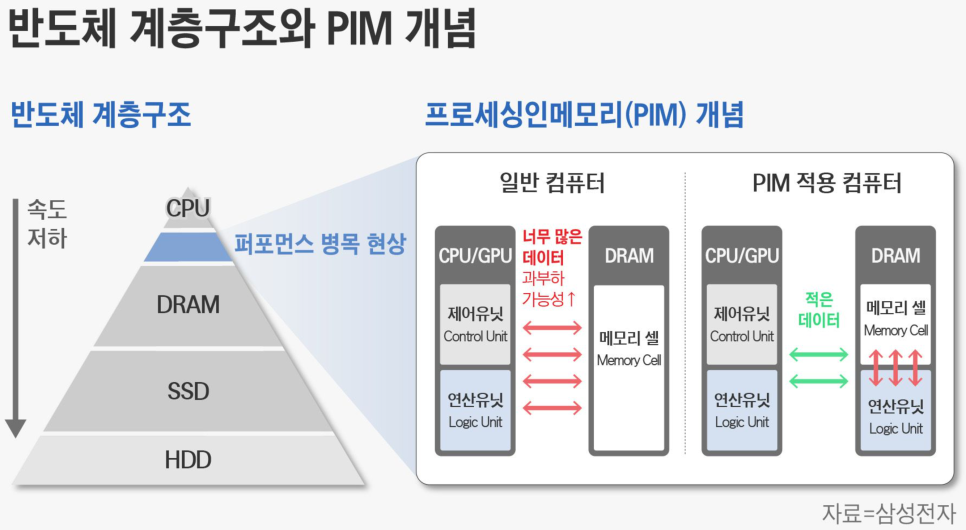
PIM은 메모리 셀 자체에서 데이터 처리를 수행함으로써 컴퓨팅 작업의 병목 현상을 최소화합니다. (CPU에서 IO에 달려있는 Memory까지 가는데 엄청나게 많은 clock swithcing이 필요합니다.) 각각의 메모리 셀은 데이터를 저장하고 처리하는 능력을 갖추며, 이러한 자체 처리 기능을 통해 CPU와 메모리 간의 데이터 이동이 줄어듭니다.
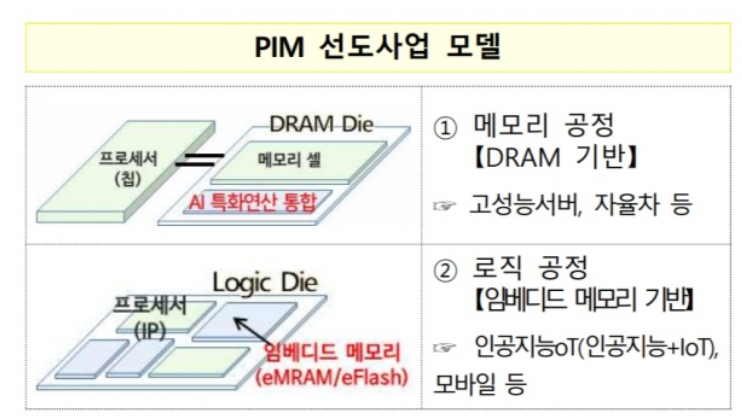
위 그림은 삼성 출처인데, 잘 보면 “CPU와 DRAM 사이”에 있다. DRAM자체는 PC에도 쓰이고, 서버용 컴퓨터에도 쓰이고, 모바일에도 쓰이고, 저가용 전자제품에도 사용된다. 굉장히 범용성이 높고.. 가격 경쟁이 심한 상품입니다.
DRAM 자체에 Processor를 넣어도 되지만, 고성능반도체가 아니라면 DRAM에 PIM 설계를 하려고하면, DRAM 단가가 올라버리니, DRAM 자체에 Processor를 넣을 수 있긴하지만, 요즘 Chiplet처럼 DRAM Interface 하는 쪽에 Processor를 넣어서 PIM을 하는 방식이 대세가 되고 있습니다.
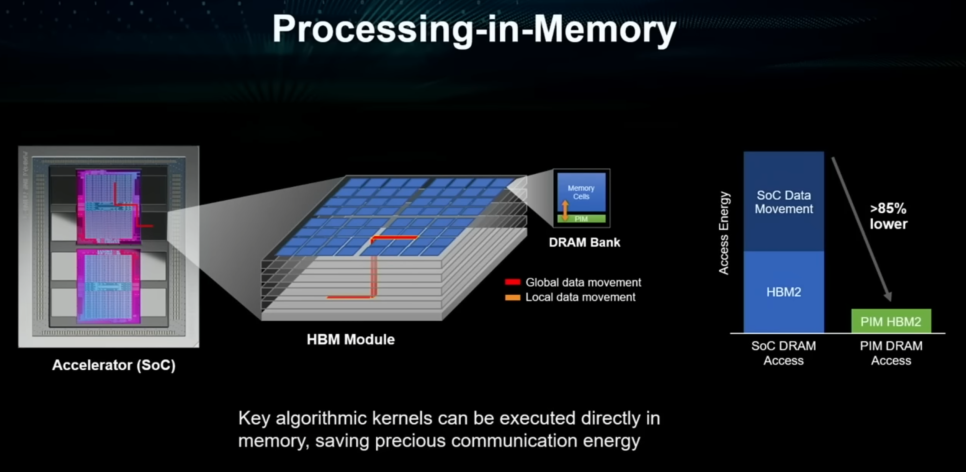
GPU / ASIC 발전으로 AI와 GPT….