
PCIe란, 디바이스 간 고속 데이터통신을 위한 IP입니다.
PC 조립을 해봤으면, ‘메인보드’라는게 있다는 것은 알 것이다. 그게 뭔진 모르더라도.
이 메인보드에는 병렬연산을 빠르게 처리하는 ‘그래픽카드(그 안에는 GPU)’, ‘사운드카드’ ‘캡쳐보드’ 등을 달아놓을 수 있는걸 알겁니다.
근데 이 PCIe.. 설계하기도 구현하기도… 매우 까다롭고 중요합니다.
ML/DL/AI, Cloud 등에선 GPU를 통한 Data를 엄청나게 주고 받아야하는데, 규모가 큰 Data 주고 받는걸 PCIe 없이 하긴 어렵거든요.
과거엔 이 메인보드에 통일된 규격이라는게 없어서, AGP, AMR, ISA, CNR 같은 다양한 규격이 존재하는 춘추전국시대였기에, 특정 메인보드엔 특정 그래픽 카드를 장착 할 수 없고.. 이런 호환성 문제가 컸습니다.
2003년에 Intel, HP, IBM, Dell에서 합작하여 규격을 발표했는데, 그것이 현재 가장 범용적인 규격인 PCI-express규격입니다.

PCIe는 아래와 같은 통신 구조를 기반하여 설계된다.
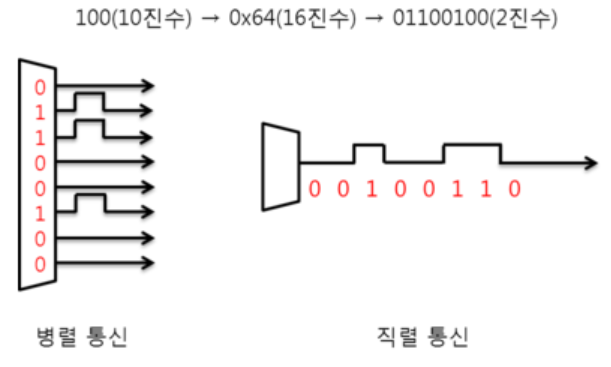
직렬 통신 : 병렬통신이 빠르긴 하지만, I/O를 많이 차지하고, I/O가 돈과 크기에 직결되고.. 다양한 이유로 대부분의 고속 통신 규격에선 직렬 통신이 쓰입니다.
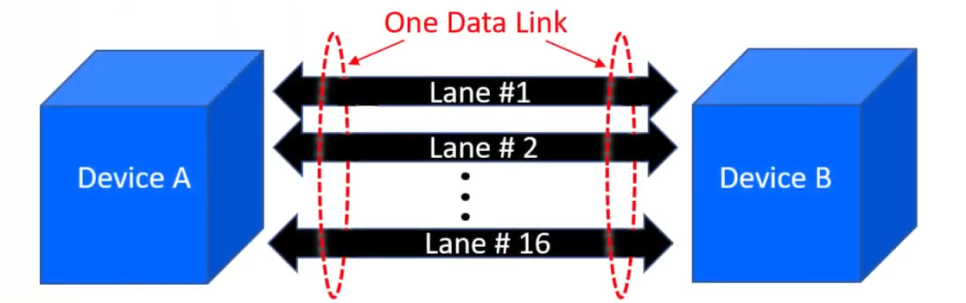
Scalable Bi-directional Point to Point Lane : Device 간 Data를 n개의 전송채널(tx), 수신채널(rx)이 Lane이라는 Data link를 통해 주고 받는다. Data link라고 썼는데, 고속도로 차선이라고 봐도 된다.실제 Hardware에서는 PMA의 pin 2 pin으로 Data를 주고 받는다고 볼 수 있다. 1lane과 16lane을 비교하면, 16lane scale이 더 많은 데이터를 보낼 수 있다.
Device A와 Device B의 tx/rx가 데이터를 주고 받는 synchronize를 맞추기 위해 동일한 Reference clock을 각 Device에 넣어줘야 한다. 이 clock으로 각 Device의 내부 clock logic이 clock을 생성한다.
근데 이 A/B는 물리적으로 떨어져있기에 Jitter 같은 Noise가 낄 수 밖에 없다. 통상적으론 100ppm을 requirement로 잡는다. 이 jitter 계산 공식이 따로 있던데, 내가 해본 적은 없다.. 아마 IP를 직접 만드는 일이 아니라면 해볼 일이 없을 것 같다.
Common clock을 기준으로 모든 Device가 이 clock을 기반으로 동작하고, 각 lane들의 Start/End point Flip Flop들은 Data clock을 통해 송수신한다.
기본적인 개념은 이러하고.. separate clock 등 PCIE3, 4, 5 버전업 되며 새로운 개념들이 추가되었지만, 추가 정보는 정리해두긴 했는데, 여기엔 안 적겠습니다.
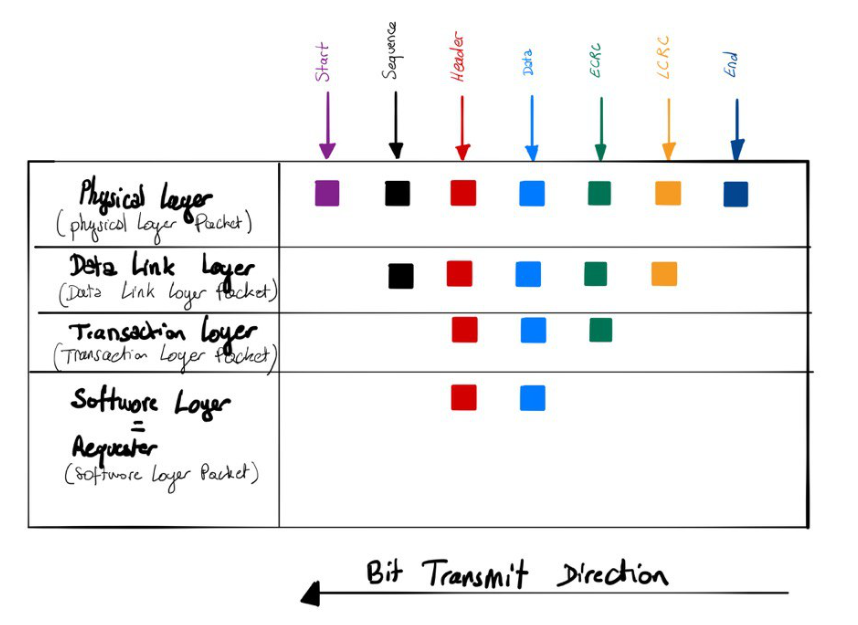
PCIe 내부 모듈은 PMA, PHY, PCS 등이 포함 됩니다. 통신 프로토콜 공학에서 배웠던 OSI 7 Layer의 일부 Layer 개념이 그대로 적용됩니다.
PHY (Physical Layer):
PHY는 전송 데이터를 물리적인 전송 신호로 변환하고 인코딩/디코딩 후 PCS에 전달
PCS (Physical Coding Sublayer):
PCS 레이어는 데이터 인코딩/디코딩, 에러 검출 및 복원, ACK, PMA 레이어에 전달
PMA (Physical Media Attachment):
PMA는 physical Media <-> PCIe device layer 간 인터페이스와 데이터 인코딩/디코딩
GPU를 제대로 쓰려면, PCIe의 Spec을 맞춰서 써야합니다…
설계자 입장에서 PCIe는 target clock 정하기도 어렵고, jitter care도 어렵고, clock이 매우 많기에 까다롭고, topogy를 고려하여 구현하기에,,, 또 까다롭습니다….